|
|
|
|
|
|
|

new view:레터가 새로운 모슴으로
찾아왔습니다.
-
더 편하게 읽으실 수 있도록 전체
레이아웃을 정리했어요.
-
중요한 내용을 빠르게 확인하실 수
있도록 정보 구성을 개선했어요.
-
다양한 콘텐츠를 더욱 자연스럽게
보실 수 있도록 화면 흐름을
바꿨어요.
|
|
|
|
|

|
|
|
|
|
수메르인의 점토판, 이집트의
파피루스, 구텐베르크의 인쇄기.
인간은 언제나 기록을 남기고, 더
많은 사람에게 닿게 하려 했습니다.
이번 호는 그 긴 여정의 가장 최신
장면을 다룹니다. 기계가 문서를
읽기 시작한 시대, 그리고 이제 AI가
문서를 '이해'하는 시대로의 전환.
어렵지 않습니다. 아마 읽다 보면
'어, 이거 내 스마트폰 얘기네' 하는
순간이 올 겁니다.
편집팀 드림
|
|
|
|
수메르인의 점토판, 이집트의
파피루스, 구텐베르크의 인쇄기.
인간은 언제나 기록을 남기고, 더
많은 사람에게 닿게 하려 했습니다.
이번 호는 그 긴 여정의 가장 최신
장면을 다룹니다. 기계가 문서를
읽기 시작한 시대, 그리고 이제 AI가
문서를 '이해'하는 시대로의 전환.
어렵지 않습니다. 아마 읽다 보면
'어, 이거 내 스마트폰 얘기네' 하는
순간이 올 겁니다.
편집팀 드림
|
|
|
|
|
|
|
|

|
|
|
|
|

|
|
|
|
|
작성자: 신윤호 LG유플러스
사내 필진 (LG AI대학원 1호 박사
& 10년차 AI엔지니어)
지금으로부터 약 5,000년 전,
메소포타미아의 수메르인들은
점토판에 쐐기 문자를 새겨
넣었습니다. 곡식 재고, 세금 기록,
왕의 명령 그 모든 것이
문서였습니다. 기록은 단순한 메모가
아니었습니다. 생존의 수단이었고,
권력의 언어였습니다.
이집트의 파피루스, 중국의 죽간,
유럽 수도원의 양피지…
인류는 어떤 재료를 쓰든 끊임없이
기록을 남겨왔습니다. 그리고 그
기록을 ‘더 많은 사람에게 닿게’
하려는 욕망 역시 멈추지
않았습니다. 15세기 구텐베르크의 인쇄술이 그
욕망에 불을 지폈고, 도서관이
생겨나고 신문이 탄생했습니다.
그렇게 인류는 수천 년에 걸쳐
문서를 ‘만들고’, ‘전달하는’ 법을
진화시켜 왔습니다. 그런데 이제는
새로운 질문이 등장했습니다. 기계가
문서를 ‘읽을’ 수 있을까요? 아니,
더 나아가 기계가 문서를 ‘이해’할
수 있을까요?
현재 우리는 단순히 문서 내의
글자를 읽는 것을 넘어 표, 수식,
레이아웃을 완벽히 이해하는 시대에
도달했습니다. 거대 언어 모델(LLM)의 추론 능력이
이 분야에 적용돼서 엄청난 성능을
보여주고 있는데요. 그렇다면 이
완벽에 가까운 모델들이 탄생하기
전까지 문서 인식 기술은 어떤
한계를 극복하며 진화해
왔을까요?
|
|
|
|
작성자: 신윤호 LG유플러스
사내 필진 (LG AI대학원 1호 박사
& 10년차 AI엔지니어)
지금으로부터 약 5,000년 전,
메소포타미아의 수메르인들은
점토판에 쐐기 문자를 새겨
넣었습니다. 곡식 재고, 세금 기록,
왕의 명령 그 모든 것이
문서였습니다. 기록은 단순한 메모가
아니었습니다. 생존의 수단이었고,
권력의 언어였습니다. 이집트의 파피루스, 중국의 죽간,
유럽 수도원의 양피지…
인류는 어떤 재료를 쓰든 끊임없이
기록을 남겨왔습니다. 그리고 그
기록을 ‘더 많은 사람에게 닿게’
하려는 욕망 역시 멈추지
않았습니다. 15세기 구텐베르크의 인쇄술이 그
욕망에 불을 지폈고, 도서관이
생겨나고 신문이 탄생했습니다.
그렇게 인류는 수천 년에 걸쳐
문서를 ‘만들고’, ‘전달하는’ 법을
진화시켜 왔습니다. 그런데 이제는
새로운 질문이 등장했습니다. 기계가
문서를 ‘읽을’ 수 있을까요? 아니,
더 나아가 기계가 문서를 ‘이해’할
수 있을까요? 현재 우리는 단순히 문서 내의
글자를 읽는 것을 넘어 표, 수식,
레이아웃을 완벽히 이해하는 시대에
도달했습니다. 거대 언어 모델(LLM)의 추론 능력이
이 분야에 적용돼서 엄청난 성능을
보여주고 있는데요. 그렇다면 이
완벽에 가까운 모델들이 탄생하기
전까지 문서 인식 기술은 어떤
한계를 극복하며 진화해
왔을까요?
|
|
|
|
|
|
Transformer OCR과
VLM(Vision-Language Model)의
차이점을 설명하는 이미지입니다.
Transformer OCR 방식:
-
이미지 분석: 표 안에 있는
"$10.00" 텍스트를 시각적으로
인식합니다.
-
특징: 글자 모양을 있는 그대로
읽어냅니다.
-
결과물: "$10.00"이라는 텍스트
데이터를 그대로 인식합니다.
-
요약: 보이는 텍스트를 그대로
인식하는 것에 집중합니다.
VLM (Vision-Language Model) 방식:
-
이미지 분석: "Price" 항목 아래에
있는 "$10.00"의 맥락을 시각
정보와 의미 정보를 결합해
이해합니다.
-
특징: 맥락과 의미를 함께
파악합니다.
-
결과물: "이 상품의 가격은
10달러입니다."와 같이 문장
형태나 의미 있는 정보로
추출합니다.
-
요약: 문맥을 이해하고 필요한
값을 능동적으로 추출합니다.
제공: LG U+ Enterprise
|
문서 인식 기술은 단순히 읽는 것을
넘어, 문서를 '이해'하는 기술로
진화하고 있습니다.
|
|
|
|
문서 인식 기술은 단순히 읽는 것을
넘어, 문서를 '이해'하는 기술로
진화하고 있습니다.
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
① OCR = 글자 찾기(Detection) +
글자 읽기(Recognition)
OCR은 사진이나 스캔 된 문서 속의
시각 정보를 기계가 읽을 수 있는
텍스트 포맷으로 변환하는 기본
기술로, 쉽게 말해 사람이 책을 보고
타이핑하는 것처럼, 기계가 이미지를
보고 그 안의 글자를 텍스트로
옮겨내는 것을 뜻합니다.
※ 일반적인 OCR의 과정: 1단계
이미지 전처리(Preprocessing) →
2단계 영역 분석 및 검출(Detection)
→ 3단계 글자 인식(Recognition) →
4단계 구조
재구성(Restructuring)
이는 마치 시험 답안지를 채점하는
과정과 비슷합니다. 먼저 종이를
반듯하게 펴고(전처리), 문제 번호와
답란의 위치를 파악한 뒤(영역
검출), 글씨를 읽고(인식),
마지막으로 표 형식에 맞게
정리합니다(구조 재구성).
② 우리 삶을 바꾸는 OCR의 활용
사례
사실 OCR은 이미 오늘 하루에도
여러 번 우리 곁에 있었습니다.
아침에 마트에서 장을 보고 영수증 사진을 찍으면,
뱅크샐러드나 토스 앱이
날짜·가게명·금액을 자동으로 읽어
가계부에 기록합니다. 퇴근길에 주차장을 나설 때 차단기가 알아서 올라가는
것도, 카메라가 번호판 글자를
순간적으로 읽어냈기 때문입니다.
해외여행 중 낯선 메뉴판 앞에서 구글 번역 앱을
켜면 카메라가 글자를 인식하는 순간
한국어로 바꿔주는 것도 마찬가지입니다. 삼성 갤럭시로
서류를 스캔하면 기울어진 종이도
반듯하게 보정되고 텍스트까지
추출되는 기능, 생각해보면 모두
같은 기술입니다. 우리가
'편리하다'고 느끼는 순간들 뒤에는
대부분 OCR이 조용히 작동하고
있습니다.
|
|
|
|
① OCR = 글자 찾기(Detection) +
글자 읽기(Recognition)
OCR은 사진이나 스캔 된 문서 속의
시각 정보를 기계가 읽을 수 있는
텍스트 포맷으로 변환하는 기본
기술로, 쉽게 말해 사람이 책을 보고
타이핑하는 것처럼, 기계가 이미지를
보고 그 안의 글자를 텍스트로
옮겨내는 것을 뜻합니다.
※ 일반적인 OCR의 과정: 1단계
이미지 전처리(Preprocessing) →
2단계 영역 분석 및 검출(Detection)
→ 3단계 글자 인식(Recognition) →
4단계 구조
재구성(Restructuring)
이는 마치 시험 답안지를 채점하는
과정과 비슷합니다. 먼저 종이를
반듯하게 펴고(전처리), 문제 번호와
답란의 위치를 파악한 뒤(영역
검출), 글씨를 읽고(인식),
마지막으로 표 형식에 맞게
정리합니다(구조 재구성).
② 우리 삶을 바꾸는 OCR의 활용
사례
사실 OCR은 이미 오늘 하루에도
여러 번 우리 곁에 있었습니다.
아침에 마트에서 장을 보고 영수증 사진을 찍으면,
뱅크샐러드나 토스 앱이
날짜·가게명·금액을 자동으로 읽어
가계부에 기록합니다. 퇴근길에 주차장을 나설 때 차단기가 알아서 올라가는
것도, 카메라가 번호판 글자를
순간적으로 읽어냈기 때문입니다.
해외여행 중 낯선 메뉴판 앞에서 구글 번역 앱을
켜면 카메라가 글자를 인식하는 순간
한국어로 바꿔주는 것도 마찬가지입니다. 삼성 갤럭시로
서류를 스캔하면 기울어진 종이도
반듯하게 보정되고 텍스트까지
추출되는 기능, 생각해보면 모두
같은 기술입니다. 우리가
'편리하다'고 느끼는 순간들 뒤에는
대부분 OCR이 조용히 작동하고
있습니다.
|
|
|
|
|
|
|
|
|

|
|
|
|
|
용어만 보면 멀게 느껴지지만, 실제
현장 이야기를 들으면 달라집니다.
이 기술들이 어떻게 진화해 왔는지,
한 걸음 더 들어가
보겠습니다.
|
|
|
|
용어만 보면 멀게 느껴지지만, 실제
현장 이야기를 들으면 달라집니다.
이 기술들이 어떻게 진화해 왔는지,
한 걸음 더 들어가
보겠습니다.
|
|
|
|
|
|
|

-
OCR (optical Character
Recognition, 광학 문자 인식)
카메라로 찍은 사진 속 글자를
기계가 읽어 텍스트로 바꾸는
기술입니다. 사람이 손으로 받아쓰던
작업을 기계가 대신하는 것 그게
전부입니다.
-
딥러닝(Deep Learning) 수백만 장의
이미지를 보며 스스로 패턴을 익히는
방식입니다. 문제를 수백만 개
풀어보며 감을 익히는 학생을
떠올리면 됩니다. 규칙을 외우는 게
아니라, 경험으로 배웁니다.
-
VLM (Vision-Language Model,
시간-언어 모델) '눈'(이미지
인식)과 '뇌'(언어 이해)를 하나로
합친 AI입니다. 글자를 읽는 걸
넘어, 표의 구조와 문서의 논리까지
이해합니다. 단순 받아쓰기가 아닌
'독해'에 가깝습니다.
-
2-Stage 파이프라인 분업
시스템입니다. 문서를
텍스트,표,이미지 구역으로 나눈 뒤,
각각 따로 처리하고 마지막에
합칩니다.
-
엔드투엔드 (End-to-End) 만능
직원입니다. 하나의 모델이 문서
전체를 처음부터 끝까지 통째로
처리합니다. 아직은 2-Stage보다
속도와 정확도가 낮지만, 빠르게
따라잡고 있습니다.
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
텍스트 인식 기술은 ‘규칙’에서
‘데이터’로, 그리고 최종적으로
‘맥락(context)’을 이해하는
방향으로 발전했습니다. 1세대는 '글자 도장
찍어보기'입니다. 미리 만들어 둔
글자 모양과 하나하나 비교해서 맞는
걸 찾는 방식이라, 손글씨나
기울어진 글자는 전혀 못
읽었습니다.
2세대는 '벼락치기 달인'입니다.
수백만 장의 글자 이미지를 학습해
스스로 감을 익혔고, 처음 보는
글씨체도 어느 정도 읽어낼 수 있게
됐습니다. 3세대는 '문서를 이해하는
편집자'입니다. 글자를 읽는 걸
넘어, 이 표가 몇 행 몇 열인지,
제목과 본문의 관계는 무엇인지까지
파악합니다.
|
|
|
|
텍스트 인식 기술은 ‘규칙’에서
‘데이터’로, 그리고 최종적으로
‘맥락(context)’을 이해하는
방향으로 발전했습니다. 1세대는 '글자 도장
찍어보기'입니다. 미리 만들어 둔
글자 모양과 하나하나 비교해서 맞는
걸 찾는 방식이라, 손글씨나
기울어진 글자는 전혀 못
읽었습니다. 2세대는 '벼락치기
달인'입니다. 수백만 장의 글자
이미지를 학습해 스스로 감을
익혔고, 처음 보는 글씨체도 어느
정도 읽어낼 수 있게 됐습니다.
3세대는 '문서를 이해하는
편집자'입니다. 글자를 읽는 걸
넘어, 이 표가 몇 행 몇 열인지,
제목과 본문의 관계는 무엇인지까지
파악합니다.
|
|
|
|
|
|
OCR 기술의 세대별 발전 과정을
설명하는 이미지입니다. 1세대 기계적
패턴 매칭부터 3세대 VLM 기반
기술까지의 특징을 담고 있습니다.
1세대 (1980~2000s): 기계적 패턴
매칭 - "글자 도장 찍어보기"
-
프로세스: 입력 이미지를 미리
정의된 템플릿(글꼴)과 비교하여
인식 결과를 도출합니다.
-
대표 기술: 템플릿 매칭(Template
Matching), HMM(Hidden Markov
Model), 초기 버전의 Tesseract.
-
특징: 엄격한 규칙 기반으로
작동하며, 픽셀의 형태를 미리
정의된 글꼴과 직접 비교합니다.
2세대 (2010s): 딥러닝 - "벼락치기
달인"
-
프로세스: 입력 이미지를
CNN(시각적 특징 추출)과 RNN(순서
정보 학습)을 거쳐 데이터로
인식합니다.
-
대표 기술: CNN + RNN(CRNN),
CTC(Connectionist Temporal
Classification) 기반 파이프라인.
-
특징: 시각적 특징을 데이터로
학습하고, 순서대로 문맥을
파악하기 시작한 단계입니다.
3세대 (2020s~현재): VLM과 공간적
추론 (Multimodal Brain) - "문서를
이해하는 편집자"
-
프로세스: 문서 전체를 언어적으로
이해하여 JSON, Markdown 등
구조화된 데이터로 추출합니다.
-
대표 기술: Transformer,
Vision-Language Model(VLM).
-
특징: 문서 전체 레이아웃과
논리를 언어적으로 이해하여
구조화된 데이터로 직접 번역 및
추출합니다.
제공: LG U+ Enterprise
|
|
|
|
|
|
1세대(1980~2000s): 기계적
패턴 매칭
• 대표 기술: 템플릿
매칭(Template Matching),
HMM(Hidden Markov Model), 초기
버전의 Tesseract
• 특징: 엄격한 규칙 기반.
픽셀의 형태를 미리 정의된 글꼴과
비교.
2세대(2010s): 딥러닝
• 대표 기술: CNN + RNN(CRNN),
CTC(Connectionist Temporal
Classification) 기반
파이프라인
• 특징: 시각적 특징을 데이터로
학습하고, 순서대로 문맥을
파악하기 시작.
3세대(2020s~현재): VLM과
공간적 추론 (Multimodal
Brain)
• 대표 기술: Transformer,
Vision-Language Model(VLM)
• 특징: 문서 전체의 레이아웃과
논리를 언어적으로 이해하여
구조화된 데이터로 직접
번역.
|
|
|
|
1세대(1980~2000s): 기계적 패턴
매칭
• 대표 기술: 템플릿 매칭(Template
Matching), HMM(Hidden Markov
Model), 초기 버전의
Tesseract
• 특징: 엄격한 규칙 기반. 픽셀의
형태를 미리 정의된 글꼴과
비교.
2세대(2010s): 딥러닝
• 대표 기술: CNN + RNN(CRNN),
CTC(Connectionist Temporal
Classification) 기반
파이프라인
• 특징: 시각적 특징을 데이터로
학습하고, 순서대로 문맥을 파악하기
시작.
3세대(2020s~현재): VLM과 공간적
추론 (Multimodal Brain)
• 대표 기술: Transformer,
Vision-Language Model(VLM)
• 특징: 문서 전체의 레이아웃과
논리를 언어적으로 이해하여
구조화된 데이터로 직접 번역.
|
|
|
|
|
|
|
|

|
|
|
|
|
VLM 기반의 OCR 모델의 탄생
트랜스포머는 뛰어난 인식률을
보였지만, 여전히 문서를 고도화된
‘이미지-텍스트 변환기’로만
취급했습니다. 단순한 시각적
인식만으로는 표의 논리적 계층
구조, 복잡한 수학 수식, 다중
단락의 읽기 순서를 완벽히 재구성할
수 없습니다.
이를 해결하기 위해, OCR 엔진에
거대 언어 모델(LLM)의 ‘뇌’를
이식하는 패러다임 전환이
필요했습니다.
이
패러다임 전환을 우리는
VLM(Vision-Language Models)이라고
불렀고, VLM은 OCR 외에도 이미지와
텍스트를 '함께' 이해하는 작업에서
이미 다양하게 사용이 되고
있습니다(예시: LG유플러스의 AI
CCTV에서의 지능형 영상분석, 생성형
얼굴을 탐지하는 Anti-DeepFake,
IPTV 미디어 컨텐츠에서의 장면 인식
등).
VLM과 함께 OCR은 더이상 단순 탐지
작업이 아닌, 고해상도 시각 정보와
방대한 언어적 지식 사이의 ‘번역 및
추론 작업’으로 진화했습니다.
VLM 기반 OCR 모델의 구조
비전 인코더가 눈으로 본 것을
고차원의 특징으로 뽑아내면, 교차
모달 어댑터가 이를 뇌가 이해할 수
있는 언어로 통역해 주고,
마지막으로 언어 모델 디코더가
맥락과 논리를 바탕으로 최종
결과물을 입 밖으로 내어놓는
구조입니다.
• Vision Encoder(비전
인코더): 비전 인코더는 '눈'입니다.
문서를 훑어보고 "여기 표가 있고,
저기 제목이 있구나"를
파악합니다.
• Cross-Modal Adapter(교차 모달
어댑터/커넥터): 교차 모달 어댑터는
'통역사'입니다. 눈이 본 것을 뇌가
이해할 수 있는 언어로
바꿔줍니다.
• LLM Decoder(언어
모델 디코더): LLM 디코더는
'뇌'입니다. 통역된 내용을 받아
문맥과 논리를 따져가며 최종
결과물을 완성합니다.
|
|
|
|
VLM 기반의 OCR 모델의 탄생
트랜스포머는 뛰어난 인식률을
보였지만, 여전히 문서를 고도화된
‘이미지-텍스트 변환기’로만
취급했습니다. 단순한 시각적
인식만으로는 표의 논리적 계층
구조, 복잡한 수학 수식, 다중
단락의 읽기 순서를 완벽히 재구성할
수 없습니다.
이를 해결하기 위해, OCR 엔진에 거대 언어 모델(LLM)의
‘뇌’를 이식하는 패러다임 전환이
필요했습니다. 이 패러다임 전환을
우리는 VLM(Vision-Language
Models)이라고 불렀고, VLM은 OCR
외에도 이미지와 텍스트를 '함께'
이해하는 작업에서 이미 다양하게
사용이 되고 있습니다(예시:
LG유플러스의 AI CCTV에서의 지능형
영상분석, 생성형 얼굴을 탐지하는
Anti-DeepFake, IPTV 미디어
컨텐츠에서의 장면 인식 등).
VLM과 함께 OCR은 더이상 단순 탐지
작업이 아닌, 고해상도 시각 정보와 방대한
언어적 지식 사이의 ‘번역 및 추론
작업’으로 진화했습니다.
VLM 기반 OCR 모델의 구조
비전 인코더가 눈으로 본 것을
고차원의 특징으로 뽑아내면, 교차
모달 어댑터가 이를 뇌가 이해할 수
있는 언어로 통역해 주고,
마지막으로 언어 모델 디코더가
맥락과 논리를 바탕으로 최종
결과물을 입 밖으로 내어놓는
구조입니다.
• Vision Encoder(비전
인코더): 비전 인코더는 '눈'입니다.
문서를 훑어보고 "여기 표가 있고,
저기 제목이 있구나"를
파악합니다.
• Cross-Modal Adapter(교차 모달
어댑터/커넥터): 교차 모달 어댑터는
'통역사'입니다. 눈이 본 것을 뇌가
이해할 수 있는 언어로
바꿔줍니다.
• LLM Decoder(언어
모델 디코더): LLM 디코더는
'뇌'입니다. 통역된 내용을 받아
문맥과 논리를 따져가며 최종
결과물을 완성합니다.
|
|
|
|
|
|
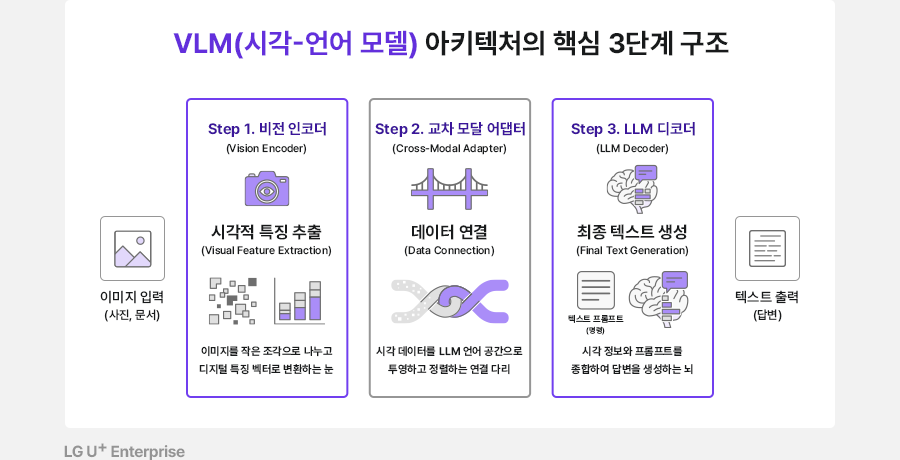
VLM(시각-언어 모델) 아키텍처의 핵심
3단계 구조를 설명하는 이미지입니다.
이미지 입력부터 텍스트 출력까지의
과정을 담고 있습니다.
Step 1. 비전 인코더 (Vision
Encoder): 시각적 특징 추출 (Visual
Feature Extraction)
-
기능: 이미지를 작은 조각으로
나누고 디지털 특징 벡터로
변환하는 '눈'의 역할을 합니다.
Step 2. 교차 모달 어댑터
(Cross-Modal Adapter): 데이터 연결
(Data Connection)
-
기능: 시각 데이터를 LLM 언어
공간으로 투영하고 정렬하는 '연결
다리' 역할을 합니다.
Step 3. LLM 디코더 (LLM Decoder):
최종 텍스트 생성 (Final Text
Generation)
-
기능: 시각 정보와 텍스트
프롬프트(명령)를 종합하여 답변을
생성하는 '뇌'의 역할을 합니다.
제공: LG U+ Enterprise
|
|
|
VLM 기반의 두 가지 핵심
아키텍쳐(파이프라인 VS
엔드투엔드)
현재 VLM 기반의 최고 성능
모델들은 크게 두 가지 방식으로 나뉩니다. 하나는 2-Stage 파이프라인
방식으로, Baidu의 Paddle-OCR과
Z.AI의 GLM-OCR이 대표적입니다.
다른 하나는 통합 엔드투엔드 방식으로, Baidu의 Qianfan-OCR과
DeepSeek의 DeepSeek-OCR2가 여기에
해당합니다.
2-Stage 방식은 쉽게 말해 '분업
시스템'입니다. 문서를 구역별로 나눈 뒤 각
전문가에게 따로 맡기는 방식으로,
두 단계에 걸쳐 OCR을 처리합니다. 첫 번째 단계는 문서
이미지 안에 있는 레이아웃을
검출(Layout Detection)하는 단계로,
텍스트·표·이미지 등을 시각적으로
분리합니다. 분리된 각 항목들은 VLM
모델에 따로 들어가 해석되고, 개별
결과는 최종적으로 통합(merge)되어
출력됩니다.
덕분에 현재 가장 높은 정확도와
빠른 속도를 자랑합니다. 단,
레이아웃 검출 자체가 잘못되면 최종
결과 전체에 영향을 미친다는 단점이
있습니다.
반면 통합 엔드투엔드 방식은 '만능
직원'에 가깝습니다. 하나의 모델이 문서 이미지를
통째로 처음부터 끝까지
처리합니다. 더욱 직관적인 방식이지만,
현재는 2-Stage와 비교해 정확도와
속도가 다소 느린 상황입니다. 이
한계를 극복하기 위해 LLM의 사고
과정에 레이아웃 분석을 결합하는
방식(예: Qianfan-OCR의
Layout-as-Thought)이나 인간처럼
문서를 읽는 방식(예:
DeepSeek-OCR2의 Visual Causal
Flow) 등 다양한 아이디어가
연구되면서 빠르게 성능이 향상되고
있습니다.
|
|
|
|
VLM 기반의 두 가지 핵심
아키텍쳐(파이프라인 VS
엔드투엔드)
현재 VLM 기반의 최고 성능
모델들은 크게 두 가지 방식으로 나뉩니다. 하나는 2-Stage 파이프라인
방식으로, Baidu의 Paddle-OCR과
Z.AI의 GLM-OCR이 대표적입니다.
다른 하나는 통합 엔드투엔드 방식으로, Baidu의 Qianfan-OCR과
DeepSeek의 DeepSeek-OCR2가 여기에
해당합니다.
2-Stage 방식은 쉽게 말해 '분업
시스템'입니다. 문서를 구역별로 나눈 뒤 각
전문가에게 따로 맡기는 방식으로,
두 단계에 걸쳐 OCR을 처리합니다. 첫 번째 단계는 문서
이미지 안에 있는 레이아웃을
검출(Layout Detection)하는 단계로,
텍스트·표·이미지 등을 시각적으로
분리합니다. 분리된 각 항목들은 VLM
모델에 따로 들어가 해석되고, 개별
결과는 최종적으로 통합(merge)되어
출력됩니다. 덕분에 현재 가장 높은
정확도와 빠른 속도를 자랑합니다.
단, 레이아웃 검출 자체가 잘못되면
최종 결과 전체에 영향을 미친다는
단점이 있습니다.
반면 통합 엔드투엔드 방식은 '만능
직원'에 가깝습니다. 하나의 모델이 문서 이미지를
통째로 처음부터 끝까지
처리합니다. 더욱 직관적인 방식이지만,
현재는 2-Stage와 비교해 정확도와
속도가 다소 느린 상황입니다. 이
한계를 극복하기 위해 LLM의 사고
과정에 레이아웃 분석을 결합하는
방식(예: Qianfan-OCR의
Layout-as-Thought)이나 인간처럼
문서를 읽는 방식(예:
DeepSeek-OCR2의 Visual Causal
Flow) 등 다양한 아이디어가
연구되면서 빠르게 성능이 향상되고
있습니다.
|
|
|
|
|
|
|
|

|
|
|
|
|
이렇게 OCR이 무엇이고 어떤
과정으로 발전되었는지를
살펴보았습니다. 저의 입사 초기에는
2세대의 CRNN 기반의 방식이
유행이었는데, 시간이 흘러 VLM
기반의 OCR 기법의 성능을 보면 흠칫
놀랄 때가 있는데요. OCR로 대표되는 문서 인식이라는
태스크는 어쩌면 모든 회사에서
필요한 일이라 여전히 폭발적으로
연구가 되고 있습니다.
만약 엔드투엔드 방식이 2-Stage
파이프라인의 성능을 완전히
뛰어넘는 시점이 온다면, OCR과 문서
인식 업계에는 일종의
‘특이점(Singularity)’이 찾아올지도
모릅니다.
그 시점의 가장 큰 변화는 AI가
문서를 사람처럼 ‘맥락 단위’로
이해하기 시작한다는
점입니다.
지금까지의 OCR은 문서를
텍스트·표·차트·이미지 등으로 잘게
나눈 뒤 각각 따로 읽는 방식에
가까웠습니다. 하지만 이상적인
엔드투엔드 VLM은 문서를 통째로
입력받아 각 요소의 관계와 의미를
함께 이해하게 됩니다.
예를 들어 기존 방식에서는 문서 속
요소들이 각각 독립적으로
인식됩니다. “신입사원
김유플”이라는 텍스트가 있더라도
옆의 사진은 단순히 “남성 사진”,
함께 있는 차트는 “연간 매출
그래프” 정도로 개별 분석되는
식입니다.
반면 엔드투엔드 방식에서는 문서
전체의 맥락을 함께 이해하기
때문에, 해당 사진이 “신입사원
김유플의 얼굴 사진”이며 차트 또한
“김유플의 연간 매출 성과
그래프”라는 관계까지 연결해 해석할
수 있게 됩니다. 즉 OCR이 단순 텍스트 추출을 넘어,
문서 자체를 이해하는 엔진으로
진화하게 되는 것입니다.
|
|
|
|
이렇게 OCR이 무엇이고 어떤
과정으로 발전되었는지를
살펴보았습니다. 저의 입사 초기에는
2세대의 CRNN 기반의 방식이
유행이었는데, 시간이 흘러 VLM
기반의 OCR 기법의 성능을 보면 흠칫
놀랄 때가 있는데요. OCR로 대표되는 문서 인식이라는
태스크는 어쩌면 모든 회사에서
필요한 일이라 여전히 폭발적으로
연구가 되고 있습니다.
만약 엔드투엔드 방식이 2-Stage
파이프라인의 성능을 완전히
뛰어넘는 시점이 온다면, OCR과 문서
인식 업계에는 일종의
‘특이점(Singularity)’이 찾아올지도
모릅니다.
그 시점의 가장 큰 변화는 AI가
문서를 사람처럼 ‘맥락 단위’로
이해하기 시작한다는 점입니다. 지금까지의 OCR은 문서를
텍스트·표·차트·이미지 등으로 잘게
나눈 뒤 각각 따로 읽는 방식에
가까웠습니다. 하지만 이상적인
엔드투엔드 VLM은 문서를 통째로
입력받아 각 요소의 관계와 의미를
함께 이해하게 됩니다.
예를 들어 기존 방식에서는 문서 속
요소들이 각각 독립적으로
인식됩니다. “신입사원
김유플”이라는 텍스트가 있더라도
옆의 사진은 단순히 “남성 사진”,
함께 있는 차트는 “연간 매출
그래프” 정도로 개별 분석되는
식입니다. 반면 엔드투엔드
방식에서는 문서 전체의 맥락을 함께
이해하기 때문에, 해당 사진이
“신입사원 김유플의 얼굴 사진”이며
차트 또한 “김유플의 연간 매출 성과
그래프”라는 관계까지 연결해 해석할
수 있게 됩니다. 즉 OCR이 단순 텍스트 추출을 넘어,
문서 자체를 이해하는 엔진으로
진화하게 되는 것입니다.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
오늘 살펴본 연구들은 외국의
연구들이 많았는데, 한국에서도 문서 인식과 OCR을 하는
업체들이 있습니다. 대표적으로는 업스테이지, 한국 딥러닝, 사이오닉
AI
등이 있고, 이 회사들의 문서인식
솔루션의 한국어 인식 또한
훌륭합니다. 그리고 유플러스의 제가 속한 팀에서도
열심히 문서 인식을 위해 연구개발을
진행하고 있습니다.
팀의 대표적인 문서 인식
엔진으로는
'AI Parser'가 있는데, 이 엔진에서 저희는 복합적인 AI 모델을 이용하여 문서
내 텍스트를 이해하고, 표의 구조를
인식하고, 그림을 설명하는 등의
역할을 하고 있습니다.
유플러스에서 문서 인식 엔진은
기존에는 금융 분야의 영수증을
포함한 숫자가 들어간 복잡한
문서들을 처리해 오기도 했고,
네트워크, IPTV 등 문서가 있는
곳이라면 어느 곳에서나 사용할 수
있는 엔진을 만들기 위해
고군분투하고 있습니다. 앞서
설명해 드린 VLM 기반의 최신 기법들도 고객
편의를 제공하기
위해 열심히 튜닝하고
있습니다.
고객이 스마트폰으로 신분증을
찍으면 모바일 상품 가입 절차가
자동으로 완성되고, MMS로 날아오는
스팸 이미지를 분석해 고객의 불편을
사전에 차단하기도 합니다. 복잡한
계약서도 사진 한 장만 찍으면 AI가
내용을 읽고 핵심을 정리해 줍니다.
각종 문서를 AI가 읽을 수 있는
형태로 변환해 생성형 AI 에이전트의
지식으로 활용되기도 하고요.
이처럼 이미지 속 정보를 이해하는
AI 기술은 이제 문서를 넘어 영상
영역으로까지 빠르게 확장되고
있습니다. Enterprise 상품인 AI CCTV는 영상
이미지를 AI가 실시간으로 분석해
침입·화재 같은 이상 상황을 사전에
감지하고, 고객의 일상과 공간을 더
안전하게 지켜냅니다.
결국 OCR 기술이 향하는 곳은
하나입니다. 복잡한 것은 기술이
대신 읽고, 고객의 일상은 더 쉽고
편안하게, 심플리(Simply)
유플러스를 이야기하는 이유와 같은
방향입니다. 이런 장면들이 더
자연스러운 일상이 될 수 있도록, 앞으로도 좋은 제품으로 발전시켜
고객분들께 선보이겠습니다.
|
|
|
|
오늘 살펴본 연구들은 외국의
연구들이 많았는데, 한국에서도 문서 인식과 OCR을 하는
업체들이 있습니다. 대표적으로는 업스테이지, 한국 딥러닝, 사이오닉
AI
등이 있고, 이 회사들의 문서인식
솔루션의 한국어 인식 또한
훌륭합니다. 그리고 유플러스의 제가 속한 팀에서도
열심히 문서 인식을 위해 연구개발을
진행하고 있습니다. 팀의 대표적인 문서
인식 엔진으로는
'AI Parser'가 있는데, 이 엔진에서 저희는 복합적인 AI 모델을 이용하여 문서
내 텍스트를 이해하고, 표의 구조를
인식하고, 그림을 설명하는 등의
역할을 하고 있습니다.
유플러스에서 문서 인식 엔진은
기존에는 금융 분야의 영수증을
포함한 숫자가 들어간 복잡한
문서들을 처리해 오기도 했고,
네트워크, IPTV 등 문서가 있는
곳이라면 어느 곳에서나 사용할 수
있는 엔진을 만들기 위해
고군분투하고 있습니다. 앞서
설명해 드린 VLM 기반의 최신 기법들도 고객
편의를 제공하기
위해 열심히 튜닝하고
있습니다.
고객이 스마트폰으로 신분증을
찍으면 모바일 상품 가입 절차가
자동으로 완성되고, MMS로 날아오는
스팸 이미지를 분석해 고객의 불편을
사전에 차단하기도 합니다. 복잡한
계약서도 사진 한 장만 찍으면 AI가
내용을 읽고 핵심을 정리해 줍니다.
각종 문서를 AI가 읽을 수 있는
형태로 변환해 생성형 AI 에이전트의
지식으로 활용되기도 하고요.
이처럼 이미지 속 정보를 이해하는
AI 기술은 이제 문서를 넘어 영상
영역으로까지 빠르게 확장되고
있습니다.
Enterprise 상품인 AI CCTV는 영상
이미지를 AI가 실시간으로 분석해
침입·화재 같은 이상 상황을 사전에
감지하고, 고객의 일상과 공간을 더
안전하게 지켜냅니다.
결국 OCR 기술이 향하는 곳은
하나입니다. 복잡한 것은 기술이
대신 읽고, 고객의 일상은 더 쉽고
편안하게, 심플리(Simply)
유플러스를 이야기하는 이유와 같은
방향입니다. 이런 장면들이 더
자연스러운 일상이 될 수 있도록, 앞으로도 좋은 제품으로 발전시켜
고객분들께 선보이겠습니다.
|
|
|
|
|